|
I am currently a researcher at Bytedance. I received my Ph.D. degree in the NLPR, Institute of Automation, Chinese Academy of Sciences (CASIA), supervised by Prof. Zhaoxiang Zhang. Prior to that, I obtained my Bachelor's degree in Automation (Robotics) from the College of Control Science and Engineering at Zhejiang University (ZJU) in 2020. Additionally, I interned at Meituan, under the supervision of Fei Xia, and at BAAI, where I was mentored by Dr. Xinlong Wang. My overarching research passion lies in embodied understanding and planning in open-world environments, with a particular focus on exploring world models and their applications in the physical world. My research interests span computer vision, unsupervised learning, 3D perception, world models, and video generation, all aiming toward comprehensive open-world 3D scene perception and understanding. Email / Google Scholar / Github / Curriculum Vitae We are hiring interns for world model and multimodal agent related work. Please contact me at Email |

|
|
|
|
|

|
Xinlong Wang, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Zhen Li, Yuqi Wang, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Chunlei Men, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Zhongyuan Wang, Tiejun Huang Nature, 2026 [paper] [Code] Next-token prediction for large multimodal models |
|
* indicates equal contribution |

|
Yingyan Li*, Shuyao Shang*, Weisong Liu*, Bing Zhan*, Haochen Wang*, Yuqi Wang, Yuntao Chen, Xiaoman Wang, Yasong An, Chufeng Tang, Lu Hou, Lue Fan, Zhaoxiang Zhang ICLR, 2026 [paper] [Code] World Models Amplify Data Scaling Law in Autonomous Driving |
|
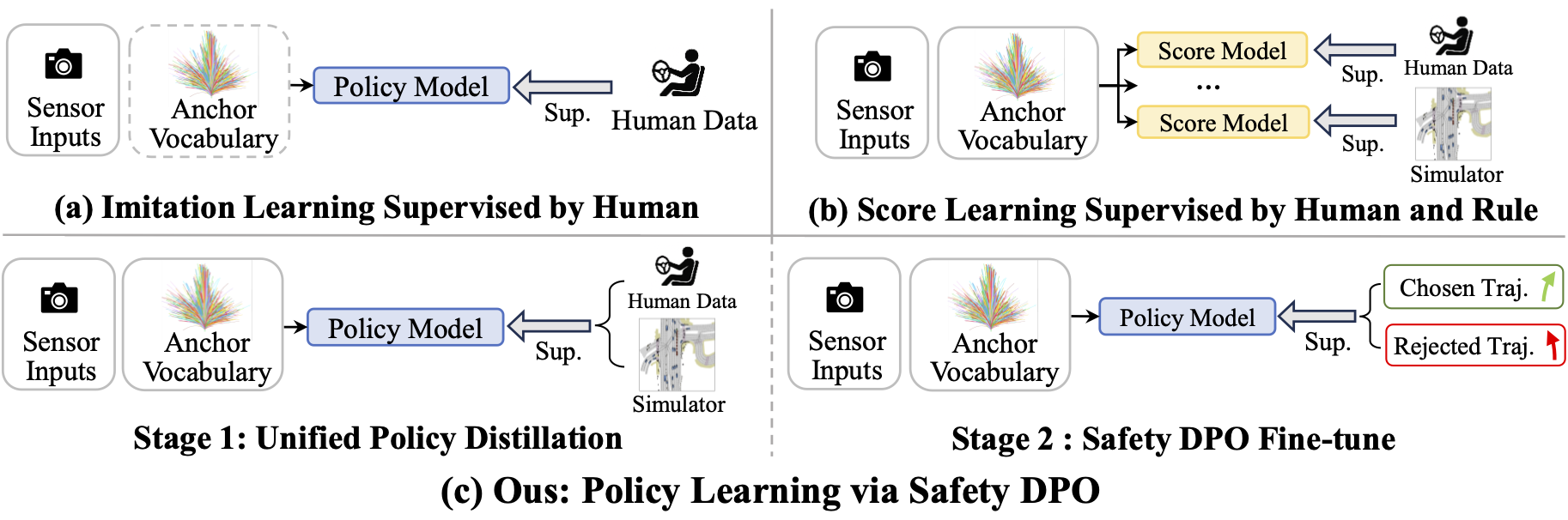
Shuyao Shang*, Yuntao Chen*, Yuqi Wang, Yingyan Li, Zhaoxiang Zhang NeurIPS, 2025 [paper] DPO for autonomous driving safety |
|
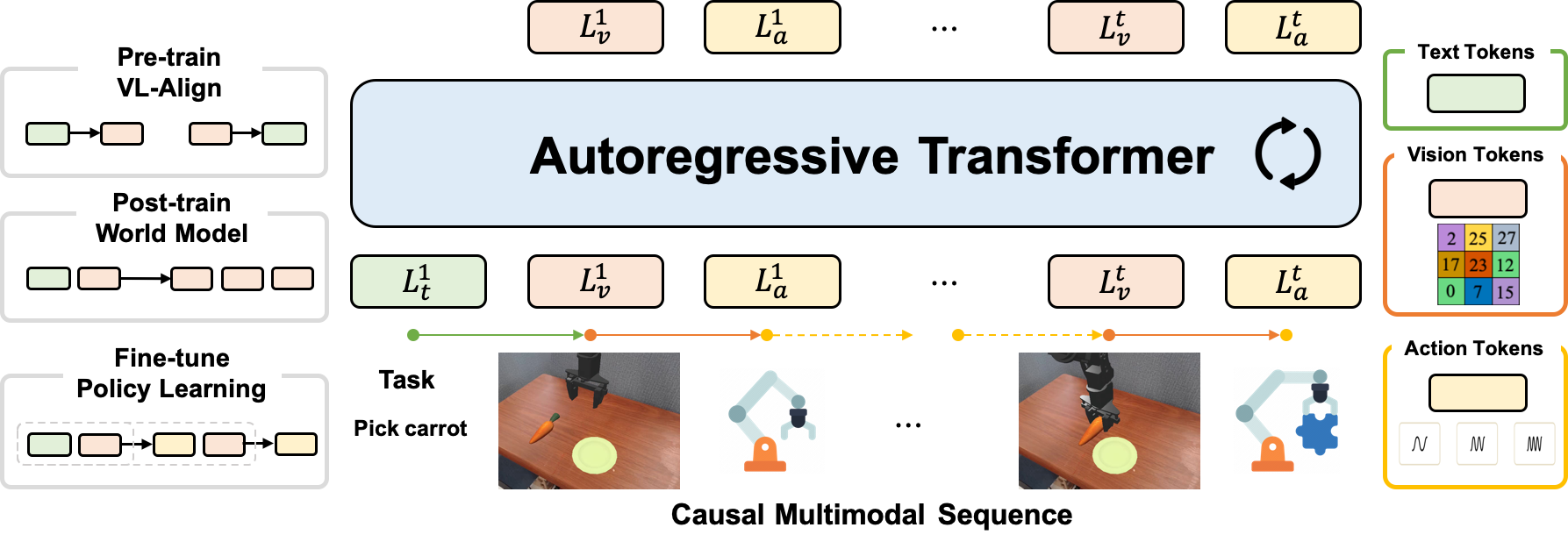
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, Zhaoxiang Zhang ICLR, 2026 [paper] [Page] [Code] unified vision-language-action model for embodied intelligence |
|
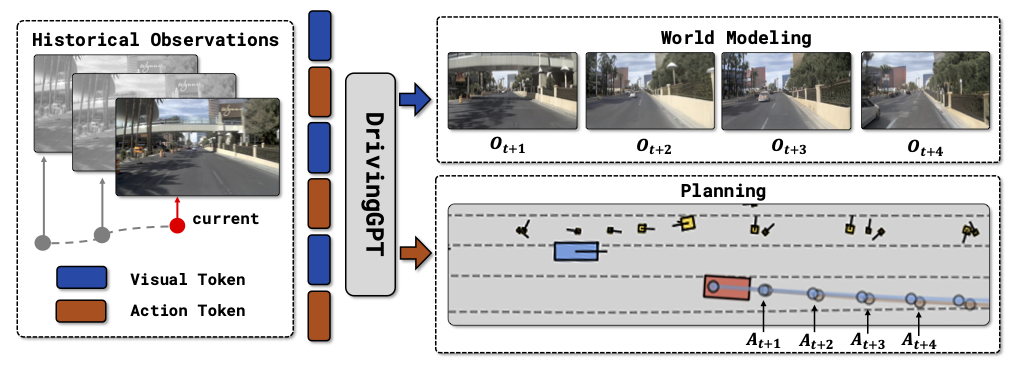
Yuntao Chen, Yuqi Wang, Zhaoxiang Zhang ICCV, 2025 [paper] [Page] Unifying world model and planning in autonomous driving |
|
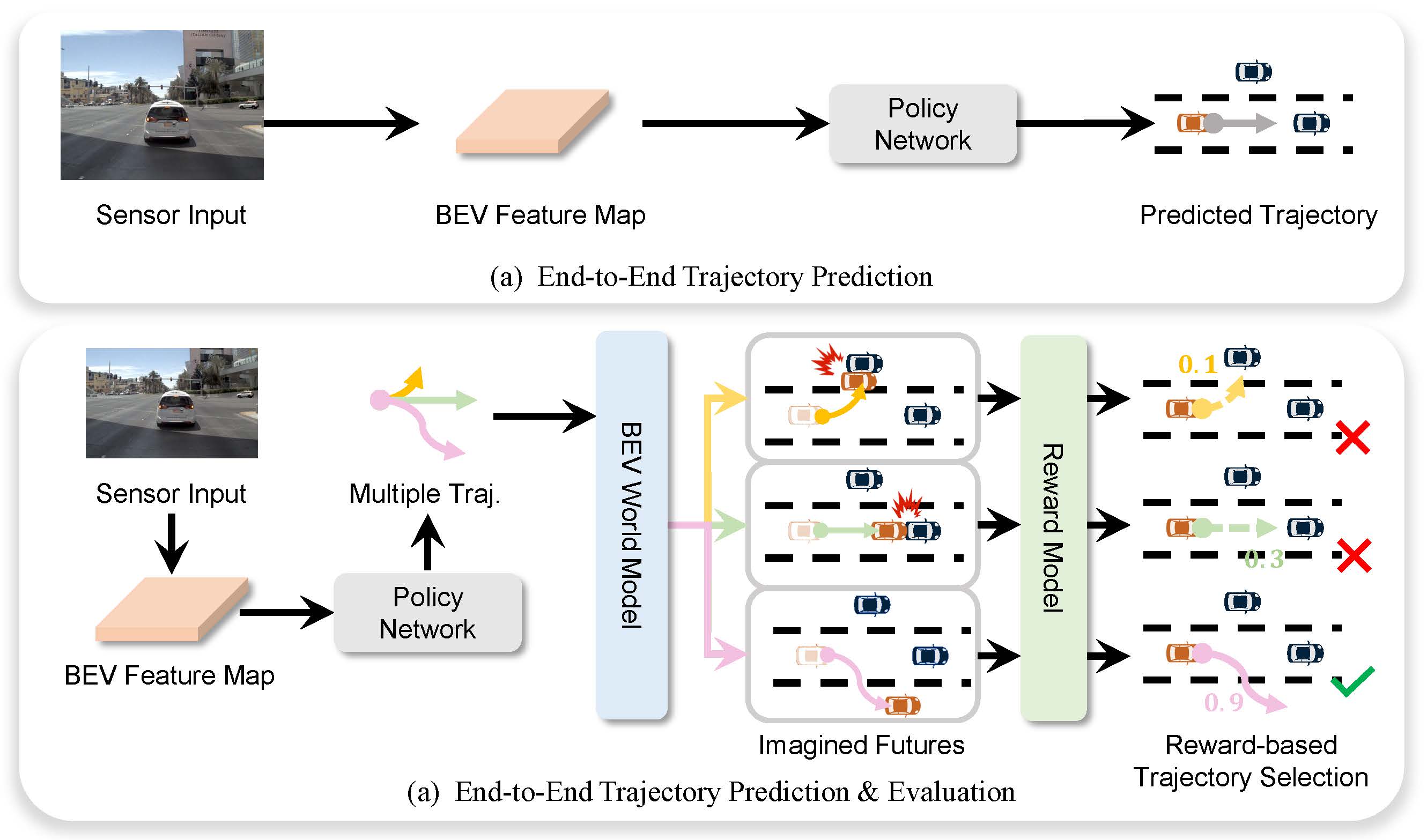
Yingyan Li*, Yuqi Wang*, Yang Liu, Jiawei He, Lue Fan, Zhaoxiang Zhang ICCV, 2025 [paper] [Code] An end-to-end autonomous driving framework that leverages a BEV-based world model to predict future agent states, enabling online trajectory evaluation and selection. |
|
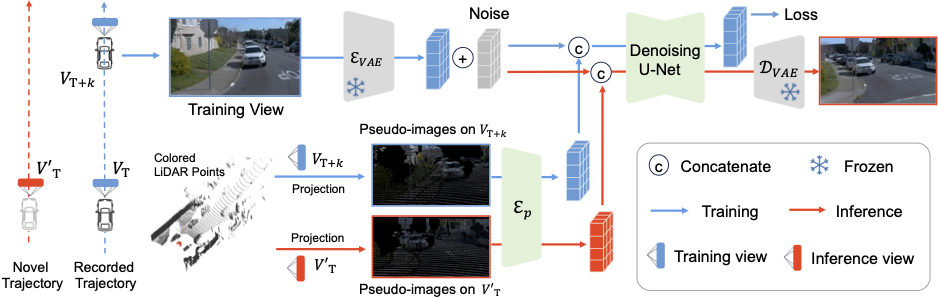
Qitai Wang, Lue Fan, Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang ICLR, 2025 [paper] [Page] [Code] Generative view synthesis on free driving trajectory |
|
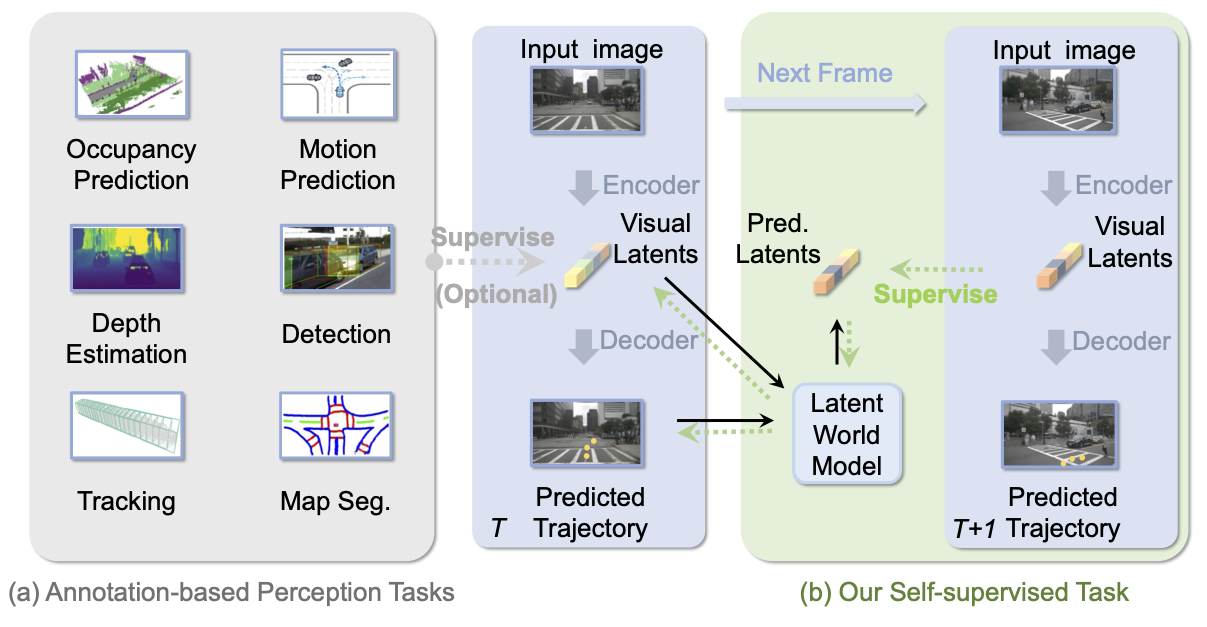
Yingyan Li, Lue Fan,Jiawei He, Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang ICLR, 2025 [paper] [Code] Latent world model as a self-supervised learning proxy for end-to-end autonomous driving |
|
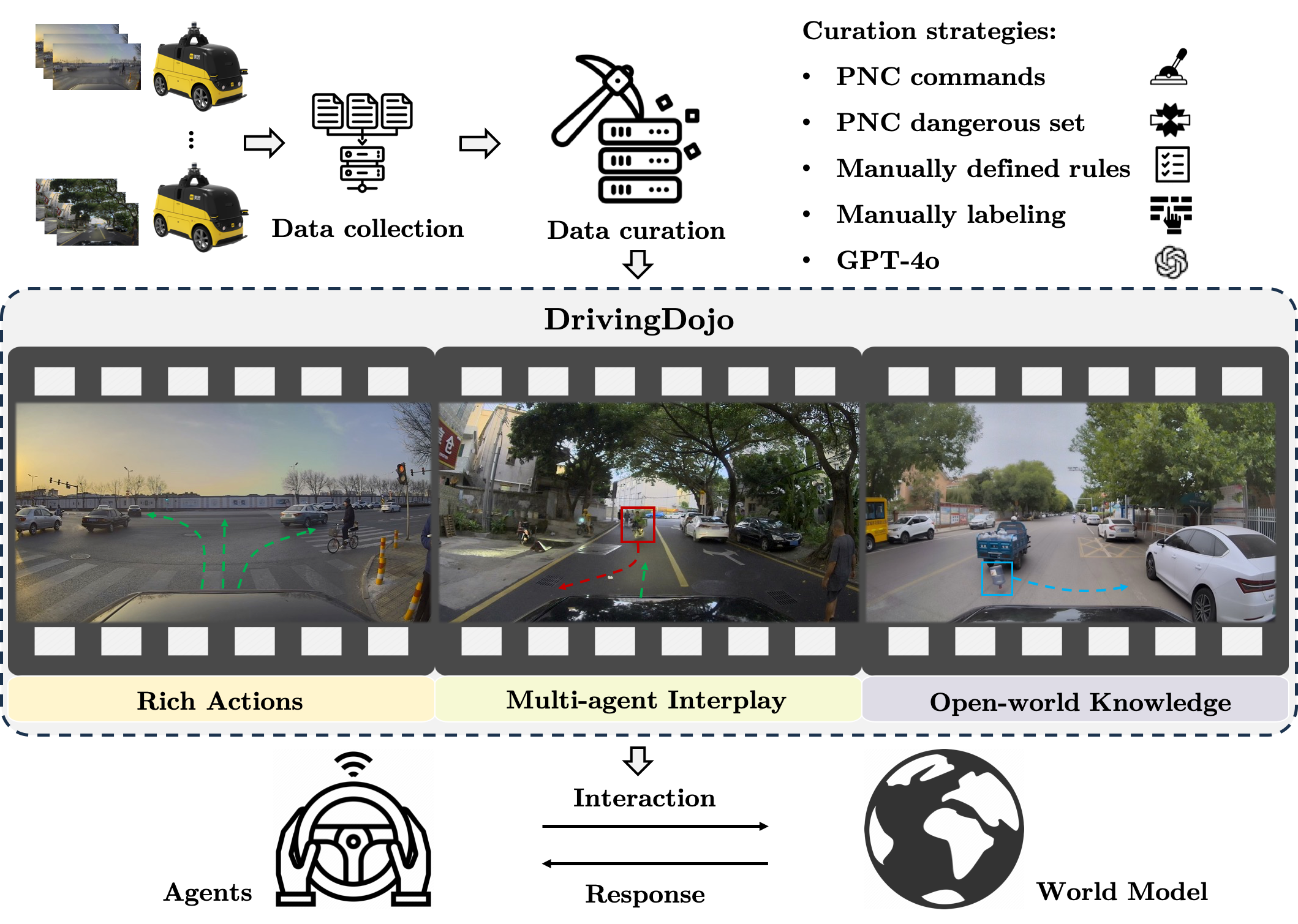
Yuqi Wang*, Ke Cheng*, Jiawei He*, Qitai Wang*, Hengchen Dai, Yuntao Chen, Fei Xia, Zhaoxiang Zhang NeurIPS, 2024, D&B Track [paper] [Page] [code] DrivingDojo dataset features video clips with a complete set of driving maneuvers, diverse multi-agent interplay, and rich open-world driving knowledge, laying a stepping stone for future world model development. |
|
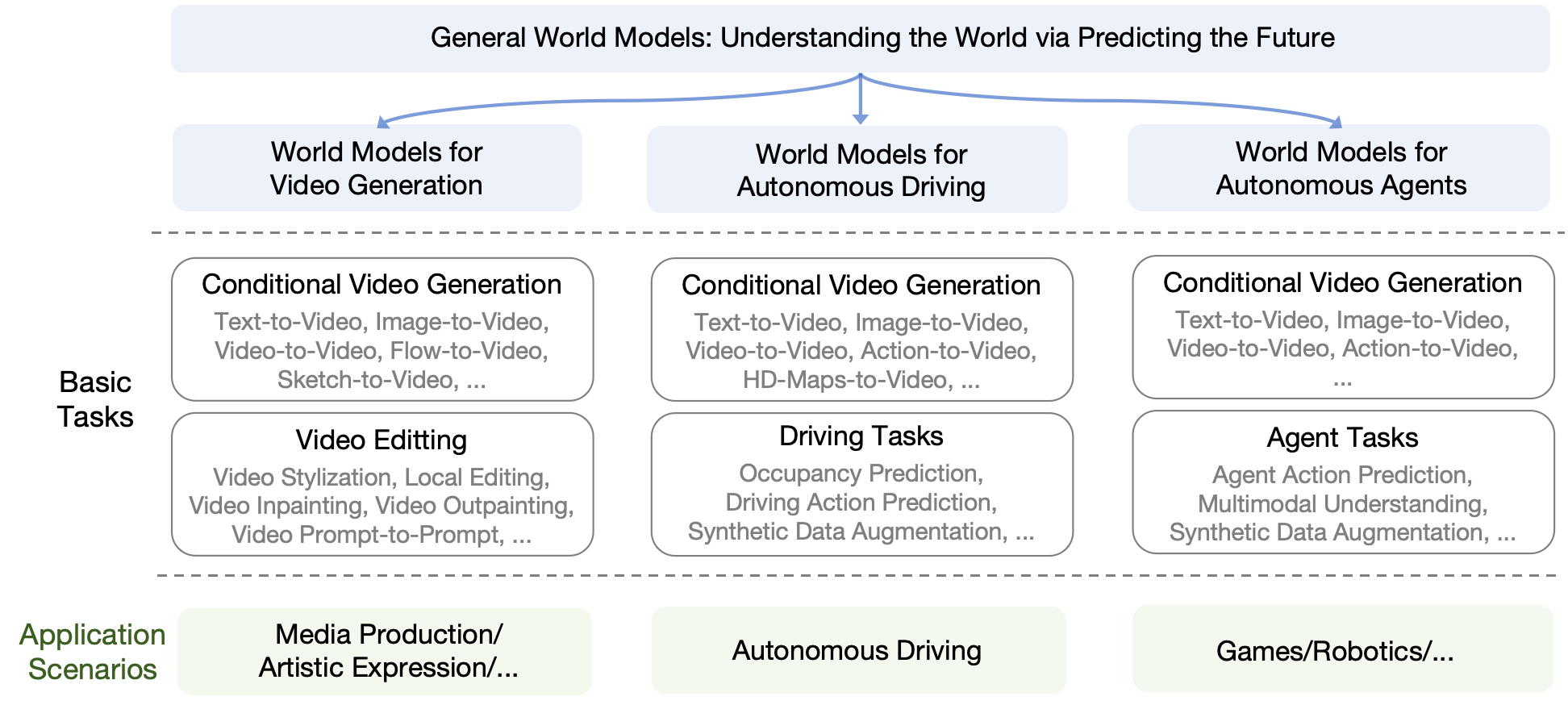
Zheng Zhu*, Xiaofeng Wang*, Wangbo Zhao*, Chen Min*, Nianchen Deng*, Min Dou*, Yuqi Wang*, Botian Shi, Kai Wang, Chi Zhang, Yang You, Zhaoxiang Zhang, Dawei Zhao, Liang Xiao, Jian Zhao, Jiwen Lu, Guan Huang arXiv, 2024 [paper] [code] A comprehensive survey on general world models, including world models for video generation, autonomous driving and autonomous agents. |
|
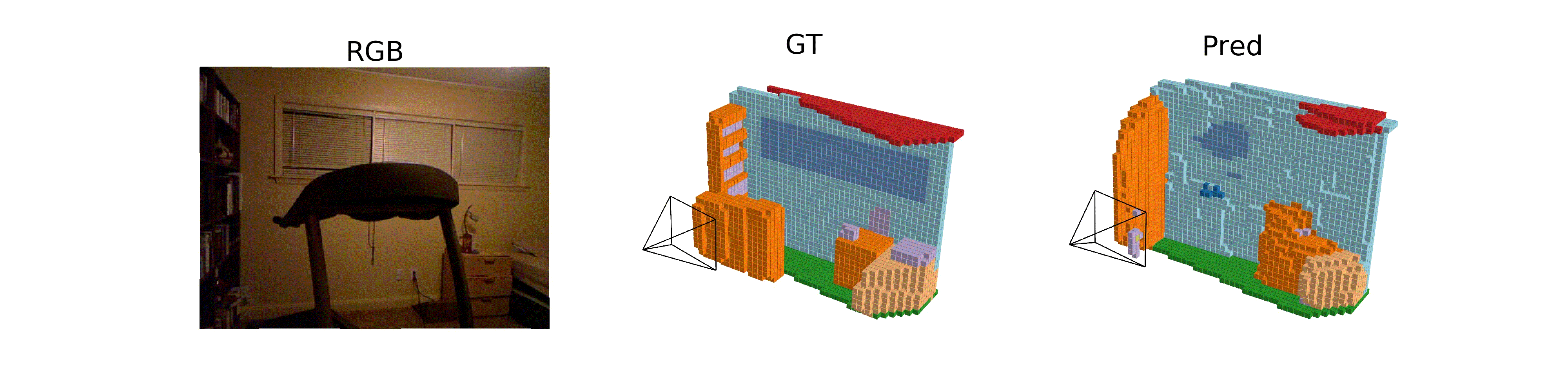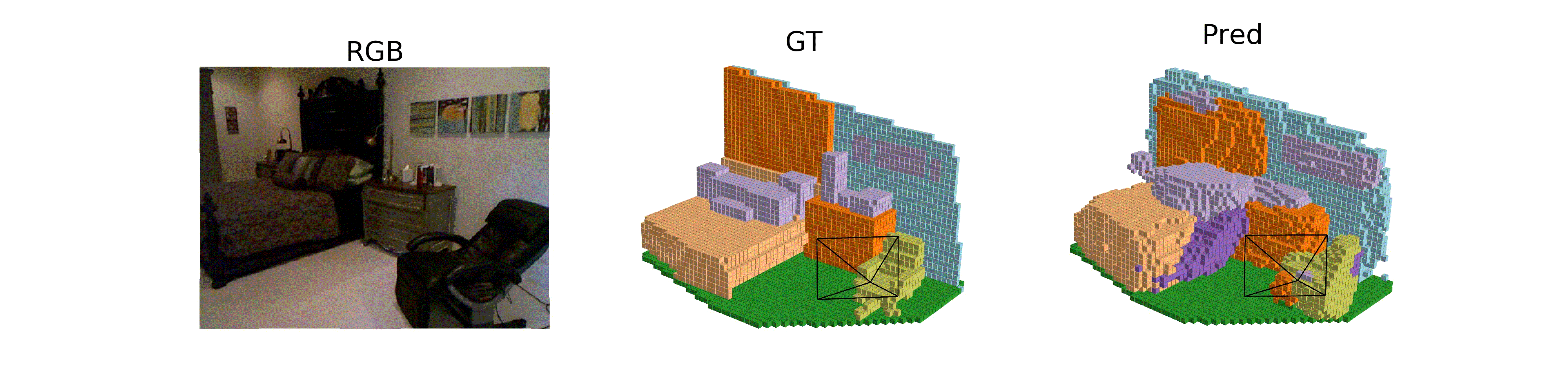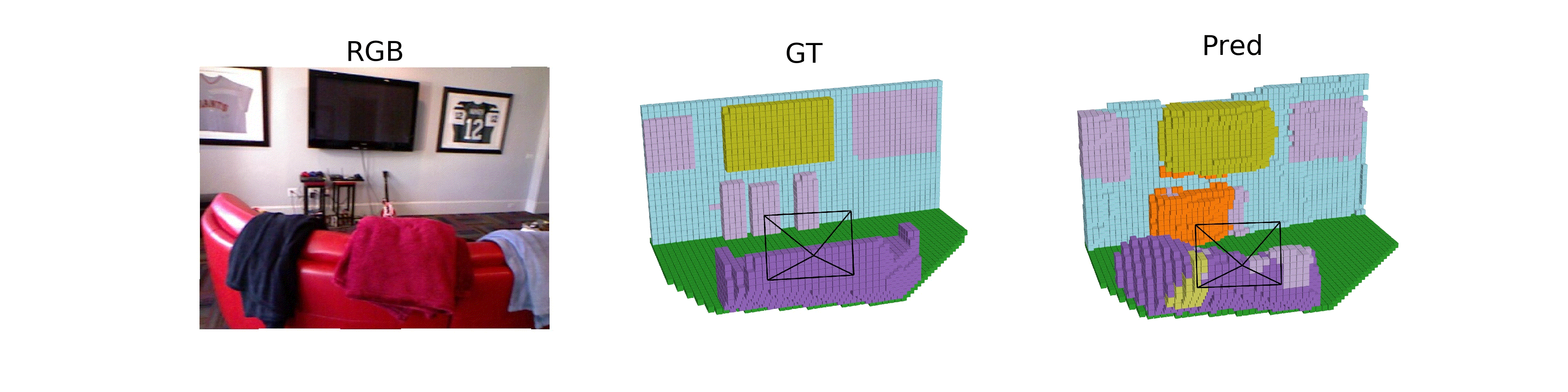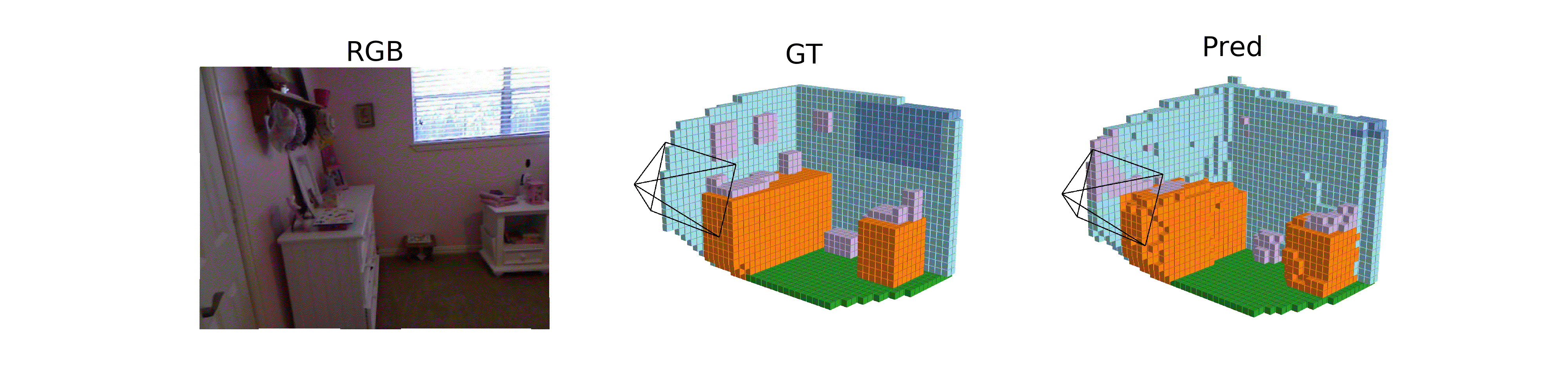
Hongxiao Yu, Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang ECCV, 2024 [paper] [page] [code] ISO, a method for monocular occupancy prediction in indoor scenes. |
|
|
Yuqi Wang*, Jiawei He*, Lue Fan*, Hongxin Li*, Yuntao Chen, Zhaoxiang Zhang CVPR, 2024 [paper] [Page] [code] Drive-WM, a pioneering multi-view world model for end-to-end autonomous driving. |
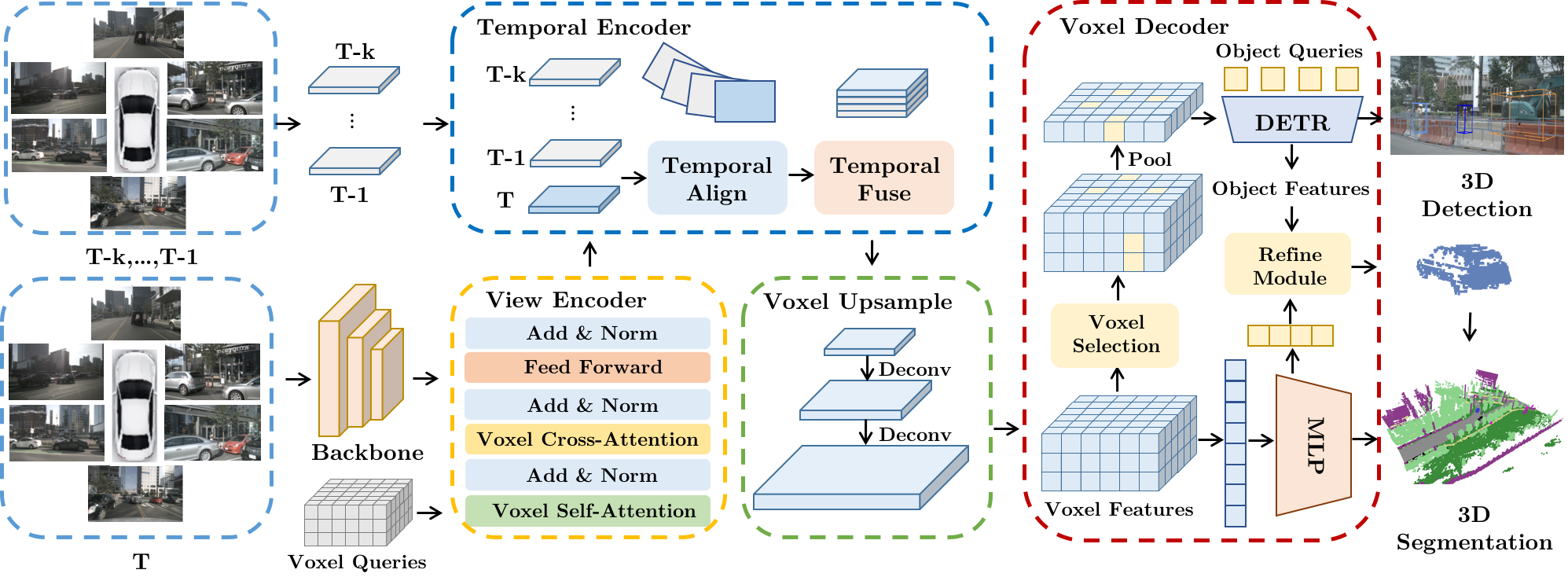
|
Yuqi Wang, Yuntao Chen, Xingyu Liao, Lue Fan, Zhaoxiang Zhang CVPR, 2024 [paper] [code] PanoOcc, a method for camera-based 3D panoptic scene understanding. |
|
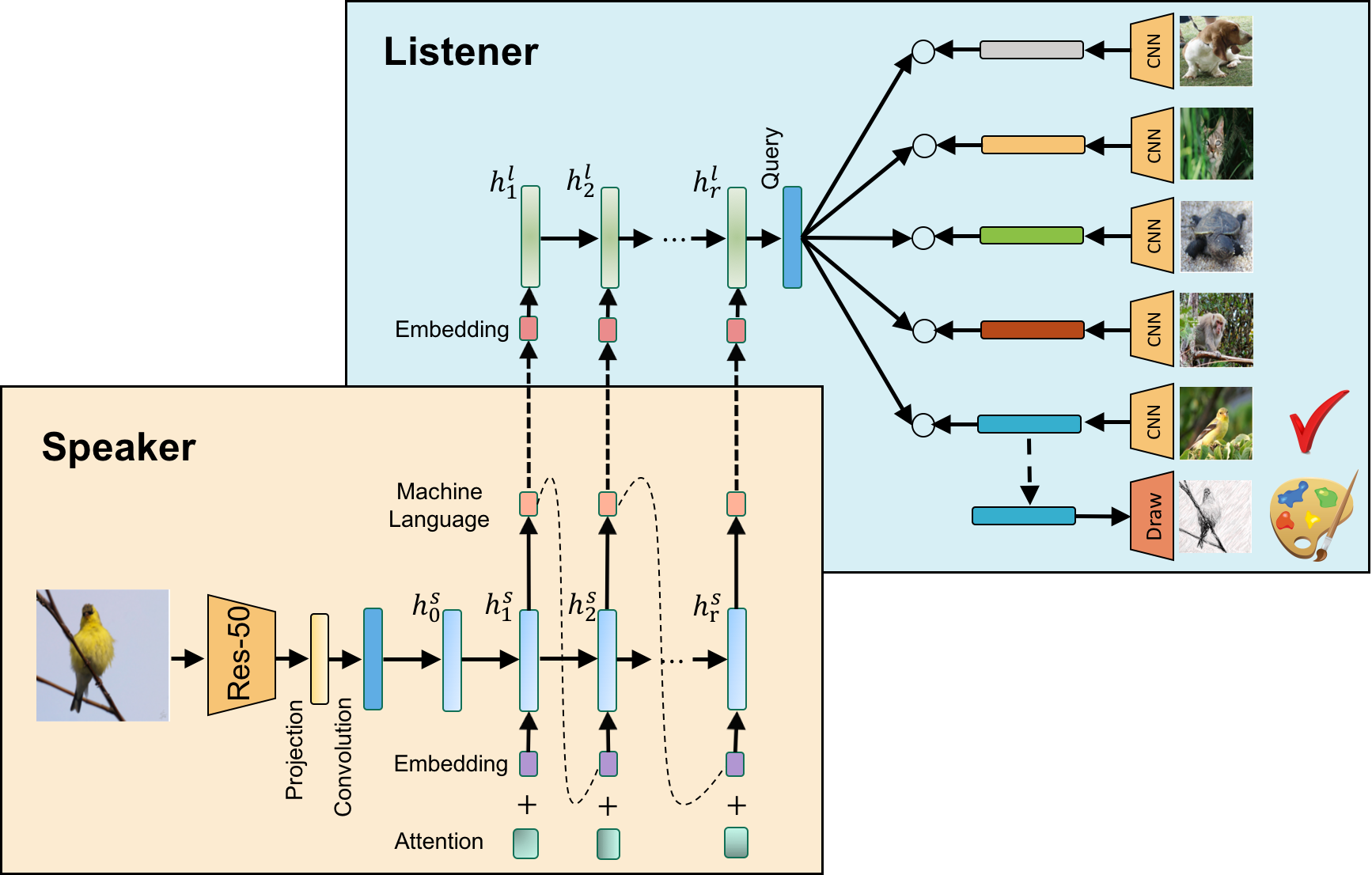
Yuqi Wang, Xu-Yao Zhang, Cheng-Lin Liu, Tieniu Tan, Zhaoxiang Zhang National Science Review (NSR), 2024 [paper] Emergence of machine language. |
|
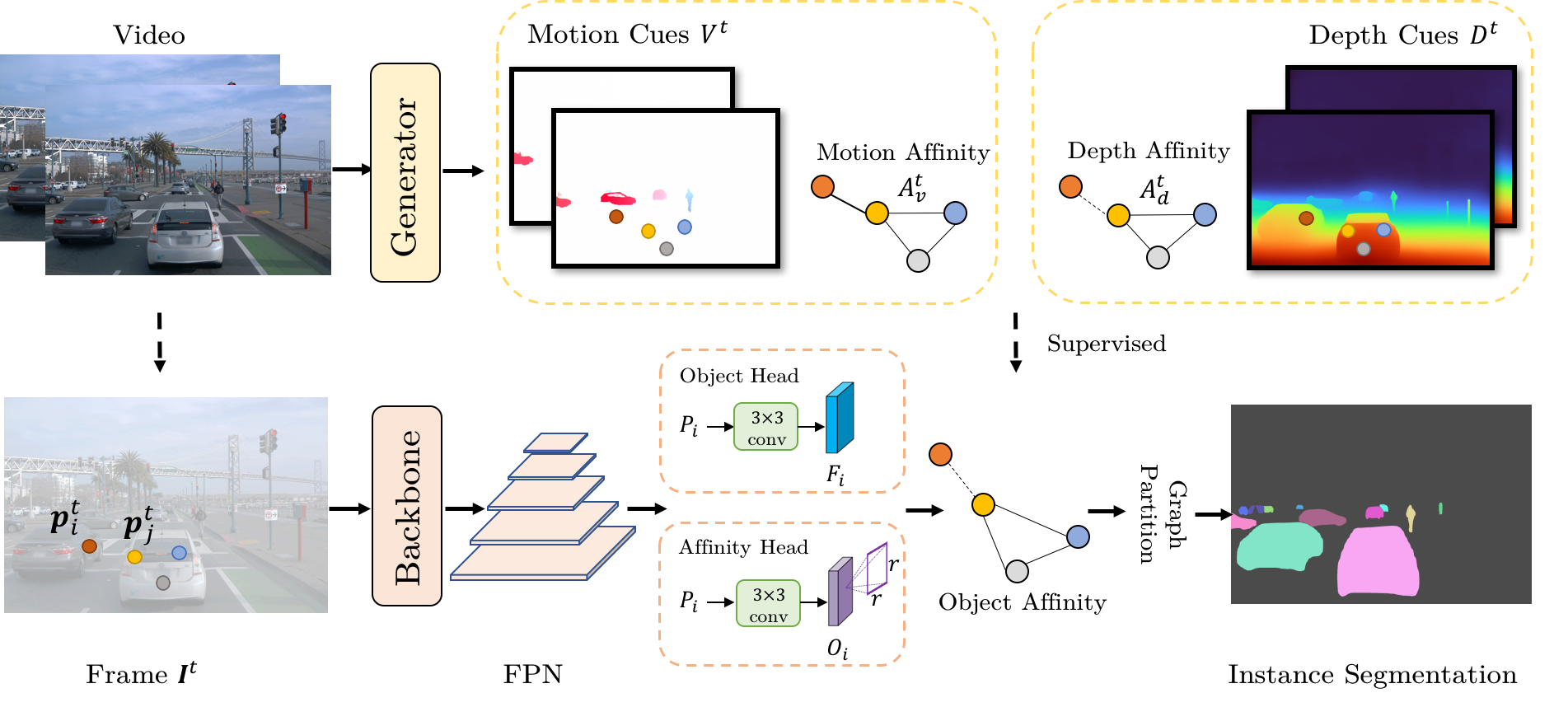
Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024 [paper] [Code] 2D object discovery through depth and flow cues. |

|
Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang CVPR, 2023 [paper] [Code] [Bilibili] FrustumFormer, enhancing vision-based 3D object detection through 2D prior. |
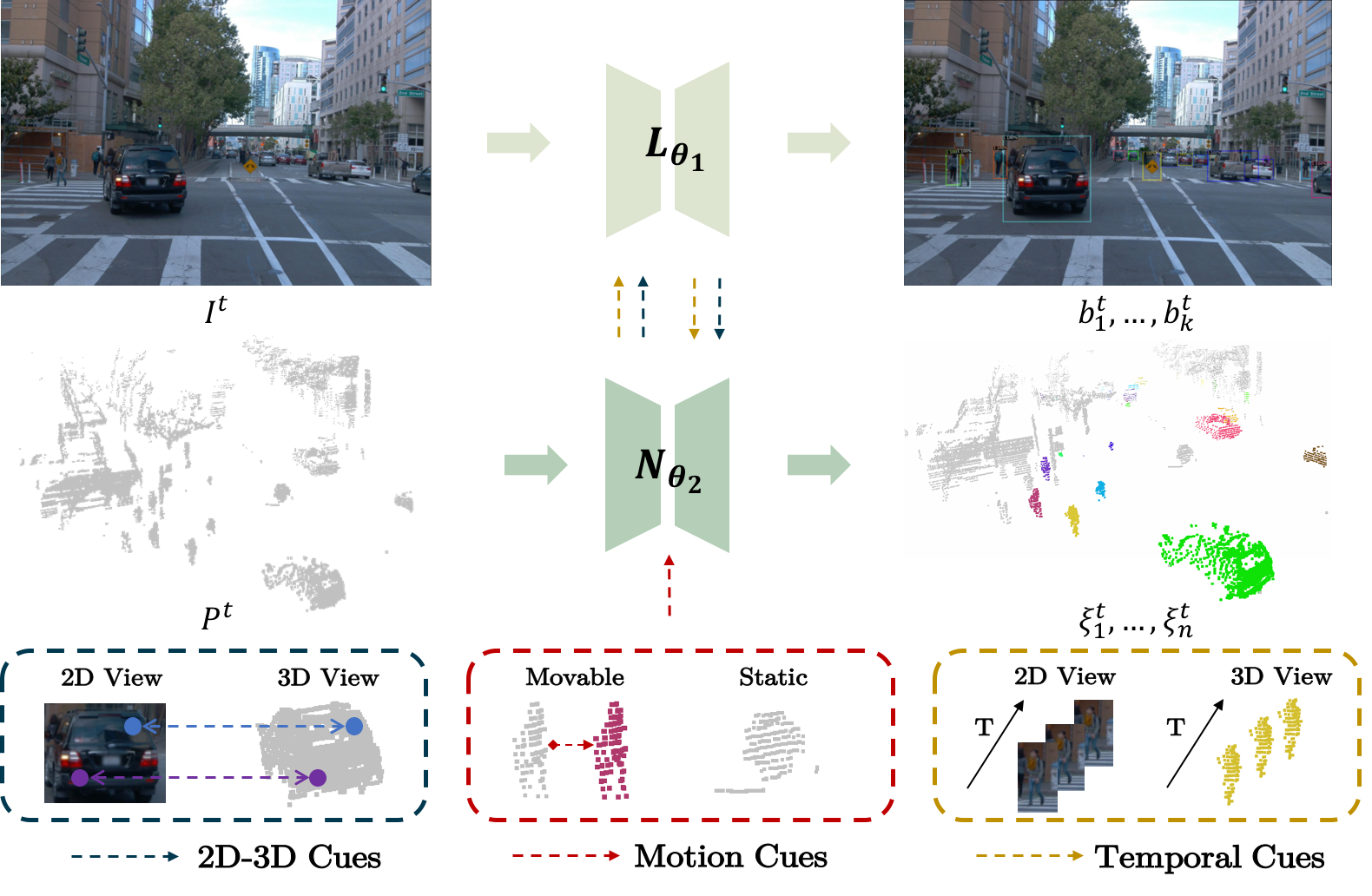
|
Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang NeurIPS, 2022, (Spotlight) [paper] [Code] 4D unsupervised object discovery using camera and LiDAR raw information. |
|
|
|
|
© Yuqi Wang | Last updated: January 31, 2026